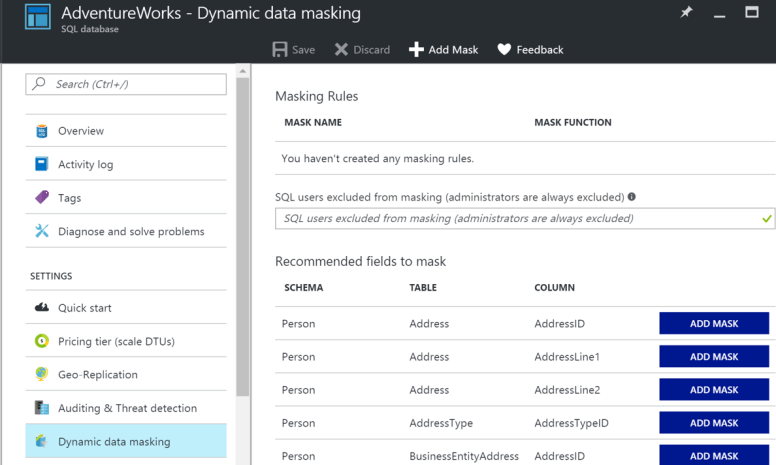
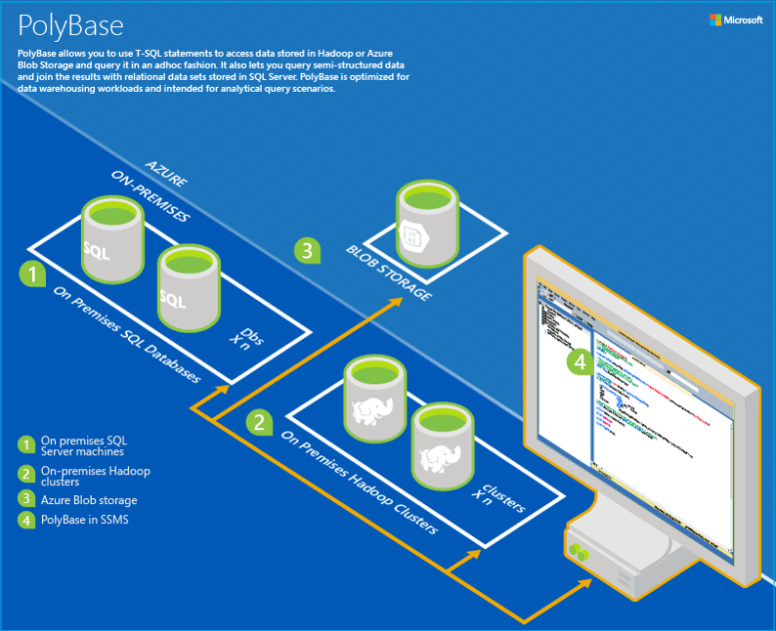
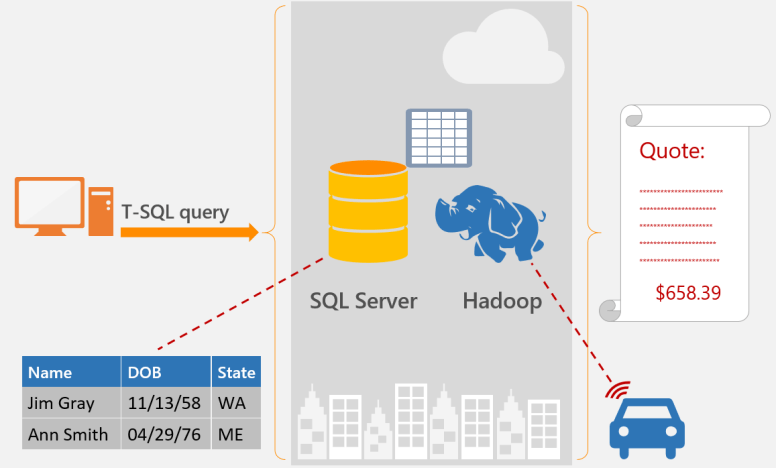
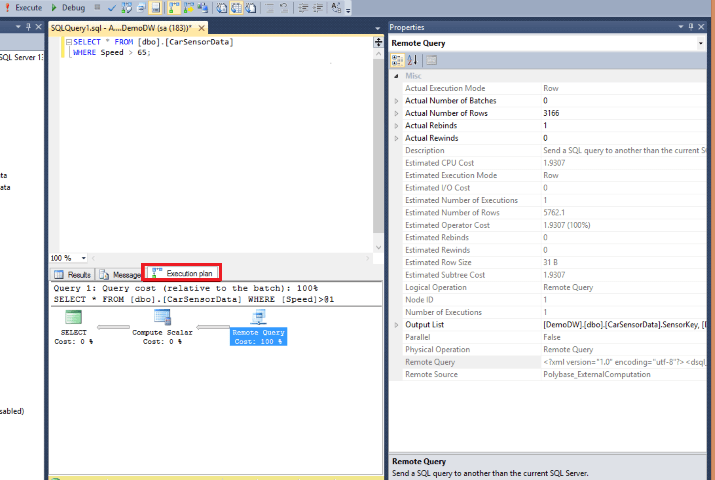
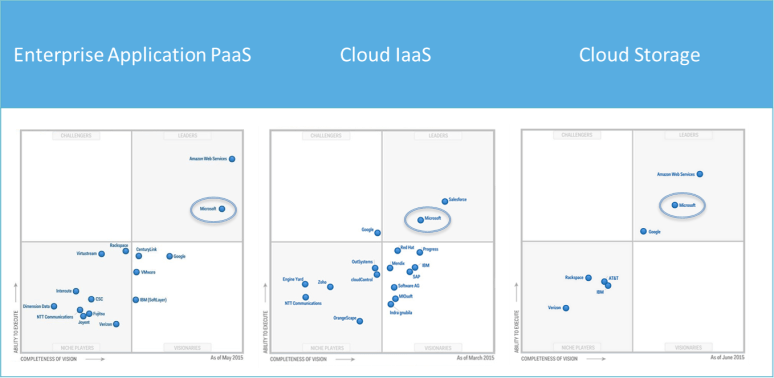
There is a lot of confusion around the traditional software life-cycle vs a data science life-cycle. Are they completely different animals? They both leverage technology that solves business problems, so we should be able to use similar techniques, right? Well, yes and no. Let’s discuss.
Half of predictive analytics projects started by companies fail “because they aren’t completed within budget or on schedule, or because they fail to deliver the features and benefits that are optimistically agreed on at their outset.” [[1]] This story is very familiar in the software development world. [[2]] Agile techniques, complemented by Development Operations (DevOps) methodologies, were developed to address some of the key challenges is bringing software projects to completion. In this post, I address one way to adapt these techniques for use in a data analytics project. [[3]]
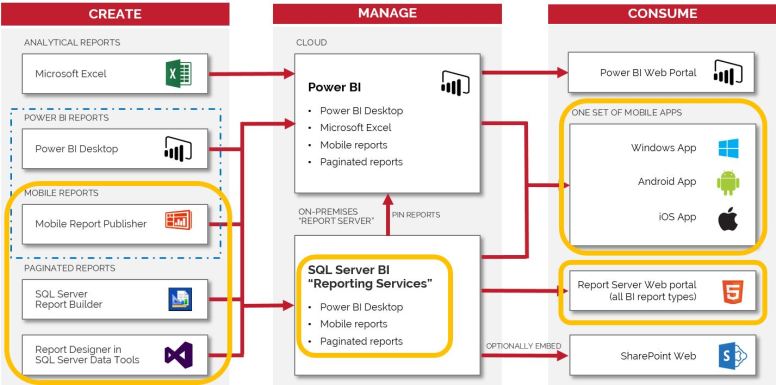
CRISP-DM Methodology
The current standard [[4]] methodology for data science projects is the Cross Industry Standard Process for Data Mining (CRISP-DM) (illustrated in the circular diagram) [[5]]. It captures the iterative nature of doing data science. Similar to traditional BI, data science is iterative by nature.
 [[6]]
[[6]]
The challenge with CRISP-DM is getting actionable results from the data science project – turning it into business processes and getting results out to decision makers. There are several potential traps in the methodology that can lead to project failure:
- Getting stuck in the Data Understanding-Data Preparation phase – Large data can be overwhelming and lead to the team getting lost in trying to match the business use cases with the available data.
- Getting stuck in the data preparation-modeling loop – This potentially can be an infinite loop without sufficient controls and focus for breaking out of the loop. There is no such thing as a perfect model, but it is hard to determine when the model is “good enough”
- Getting out of the main business understanding to evaluation loop – Data analytics projects can iterate many times over this entire loop and never break out into deployment.
A great way to avoid these traps is to combine the CRISP-DM methodology [[7]] with result-driven Agile methodology, with the integrated techniques from DevOps/DataOps [[8]].
Agile Methodology
Adapt the Agile Scrum Framework [[9]] to the needs of a data analytics project [5] by mapping the roles and events onto the CRISP-DM methodology. The resources involved in the Scrum Framework are illustrated below and can be heavily leveraged with the CRISP-DM methodology as well.
 [[10]]
[[10]]
The Scrum Team
The Product Owner
From the Scrum Guide:
The Product Owner is responsible for maximizing the value of the product and the work of the Development Team. How this is done may vary widely across organizations, Scrum Teams, and individuals. [9]
For a predictive analytics project, this is either the data science project sponsor or a member of the organizational leadership team. Having a product owner helps to provide clear guidance and direction to the data science team and keep the project focused on real business needs.
The Data Science Team
Typically called the “development team” in Agile guides and recently modified to be a DevOps team, the data science team includes everyone who is working on the data science project. From [9]:
The Development Team consists of professionals who do the work of delivering a potentially releasable Increment of “Done” product at the end of each Sprint. Only members of the Development Team create the Increment.
Likewise, a data science (or DataOps) team consists of members with complementary skills [[11]] including:
- Data engineers who are responsible for capturing, storing, and processing data;
- Data scientists who work on the data cleaning and predictive modeling;
- Business analysts who connect an understanding of the business with data understanding;
- Platform administrators who work with the data engineers and data scientists to develop deployable products; and,
- UX designers who work on the front-end data communication with the data product users.
The Scrum Master
A Scrum Master acts as the data science team guide and interface between the data science team, the product owner, and the organization.
Scrum Events
The Scrum methodology breaks up the overall project into smaller pieces of work known as sprints with the goal of producing a potentially usable product at the end of each sprint.
The heart of Scrum is a Sprint, a time-box of one month or less during which a “Done”, useable, and potentially releasable product Increment is created. Sprints best have consistent durations throughout a development effort. A new Sprint starts immediately after the conclusion of the previous Sprint. [9]
The iterative nature of the CRISP-DM doesn’t fall nicely into the more linearly-focused Agile Sprint. However, mapping key components of CRISP-DM onto Agile Sprints helps keep focus on creating usable business products at the end of each sprint.
First Sprint
The goal of the first sprint is to reach a point where the team understands the business objectives and organizational data. From the CRISP-DM method:
The first stage of the CRISP-DM process is to understand what you want to accomplish from a business perspective. Your organization may have competing objectives and constraints that must be properly balanced. The goal of this stage of the process is to uncover important factors that could influence the outcome of the project. Neglecting this step can mean that a great deal of effort is put into producing the right answers to the wrong questions. [5]
Furthermore, the sprint should gather an initial collection of data sources including the tools required for data loading. [5]
This sprint is considered “Done” when the team presents a report describing the key business issues, an inventory of available data assets, a plan for answering the top business data questions, and a description of what success will look like.
Second Sprint
To front-load the entire data process, combine several of the CRISP-DM stages into a single sprint with the goal of delivering a minimally viable predictive product at the end of the sprint. The combined CRISP-DM stages are
- Data Preparation: perform data cleaning, enrichment, and feature engineering steps
- Modelling: select and assess modeling techniques, tune model parameters
- Evaluation: evaluate model performance against the business goals
This sprint is “done” when the team either has a model that performs at an acceptable level, or has determined that the data are not sufficient to meet the business goals. In the case of an acceptable model, the goal of the sprint is to have the initial model ready for further testing and deployment into a production environment. When the data are not sufficient to meet the business goals, the sprint produces a report documenting the evidence for this outcome.
Third Sprint
In the case where the test model developed in the second sprint is meeting business goals, the goal of the third sprint is to get the model into production.
In the deployment stage you’ll take your evaluation results and determine a strategy for their deployment. If a general procedure has been identified to create the relevant model(s), this procedure is documented here for later deployment. It makes sense to consider the ways and means of deployment during the business understanding phase as well, because deployment is absolutely crucial to the success of the project. This is where predictive analytics really helps to improve the operational side of your business. [5]
The sprint is considered “done” when the team deploys a functional predictive analytics model in the production environment. At this point, the predictive analytics model can start to generate value for the business.
In the event where the second sprint finds that the business goal cannot be met with existing data, a third (and successive) sprint starts back at the beginning, selecting another business goal for evaluation or selecting a different set of data to work with.
Conclusion
Adopting this combination of Agile and CRISP-DM methodologies creates a framework for moving predictive analytics projects into the production environment where they can have a positive impact on the business. It helps teams break out of potential infinite loop traps and keep them focused on the overall goal: providing a positive return on investment for the business.
[1] http://analytics-magazine.org/the-data-economy-why-do-so-many-analytics-projects-fail/, https://www.analyticsvidhya.com/blog/2016/05/8-reasons-analytics-machine-learning-models-fail-deployed/
[3] Other posts that also look at the Agile/Data analytics mash-up: http://www.kdnuggets.com/2017/04/librarian-scientist-alchemist-engineer-dataops.html, https://www.svds.com/tbt-successful-data-teams-are-agile-and-cross-functional/
[4] http://www.kdnuggets.com/2014/10/crisp-dm-top-methodology-analytics-data-mining-data-science-projects.html
[5] http://www.sv-europe.com/crisp-dm-methodology/
[6] https://en.wikipedia.org/wiki/Cross_Industry_Standard_Process_for_Data_Mining
[7] http://www.kdnuggets.com/2017/02/real-world-results-agile-data-science-teams.html
[8] https://www.tamr.com/from-devops-to-dataops-by-andy-palmer/, ttps://en.wikipedia.org/wiki/Dataops
[9] https://www.scrumguides.org/scrum-guide.html
[10] http://agileforall.com/resources/introduction-to-agile/
[11] http://www.datasciencecentral.com/profiles/blogs/what-roles-do-you-need-in-your-data-science-team, http://www.kdnuggets.com/2015/08/3-components-successful-data-science-team.html