Flat files are one of the most common, if not the most common, data source for SSIS consumption. One of the most frequent practices in SSIS is iterating over a folder containing multiple files and processing each one independently. The most common implementation of this is by using the For Loop Container and specifying a file filter. This begs the question, “Why would a regular expression ever be needed as a file filter?”
Consider the following use case.
‘Z:/Files’ is a directory on a shared drive containing several files that need to be processed. To accomplish this, simply use the For Loop Container.

In the Collection, select ‘Foreach File Enumerator’ as the Enumerator. In the Folder, specify ‘Z:\Files’ as the file path. Specify ‘*.csv’ as the file filter. Finally, select ‘Fully qualified’ for the value of the variable. This ‘Fully qualified’ option is the easiest way to process files. This will populate the SourceFileName variable with the fully qualified path including the file name and extension, while ‘Name only’ will only have the file name without the extension, and ‘Name and extension’ will have the file name and extension without the path.
In the Variable Mapping, select a string variable that will contain the file name. In this case, it is the string variable, ‘User::SourceFileName’. Specify ‘0’ as the Index.
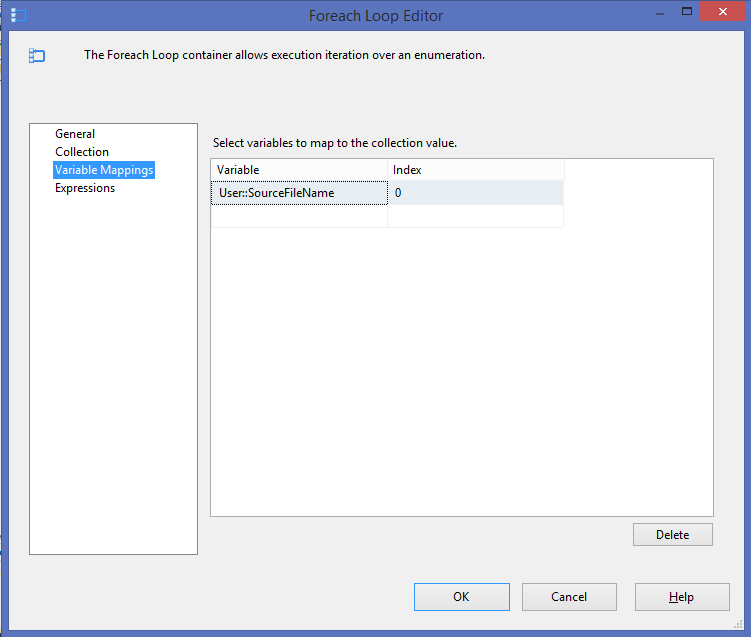
This completes the For Each Loop container. To process the file, insert a data flow within the container so the data flow executes for each file.
Continue to the data flow task and create a new destination connection, which is commonly a staging area. Next, create a new flat file connection. Continue by entering a sample file name and defining the columns and associated meta-data in the ‘Columns’ and ‘Advanced’ sections respectively.

After defining the flat file connection, right click on the ‘Flat File’ connection and use the ‘User::SourceFileName’ variable as the expression below.
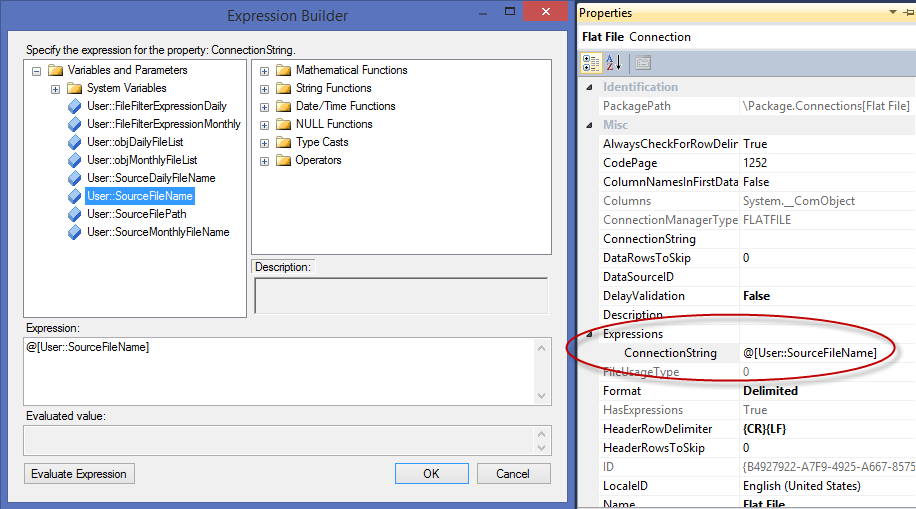
Now, every time the container iterates over another file inside the folder, the ‘Flat File’ connection will change and process that specific file. After creating the destination connection and mapping the source to the destination, the ‘DFT – Load Staging File’ data flow should be complete and look similar to the image below.
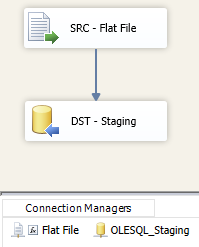
The package should now be complete. For illustrative purposes, this simplified package does not include logging, notifications, file archiving, or other miscellaneous best practices.
The completed package will processes all of the files in the specified directory with the specified file filter. As more and more files collect in the folder, the package continues to process as normal. However, consider the possibility that one day there are both monthly and daily files in the same directory, but there is a requirement for separate destinations.
Say for example, one file labeled ‘20151007AUTH9339’ includes daily transactions for October 7th, 2015 (‘20151007’), with a business alias attached of ‘AUTH’ (in this case referring to authorizations), and appended with a company code (9339) all within the file name. Another file labeled ‘201510AUTH9339’ includes monthly transactions for October 2015 (‘201510’), contains the same business alias of ‘AUTH’ and the same company code all within the file name. These files are similar, but the monthly file contains all transactions for the entire month. For the sake of simplicity, assume that the meta-data for each is the same. However, the customer wants all daily data in one table but all monthly data in another. They then perform a reconciliation process between the monthly file and daily files to ensure all transactions are correct.
One possible way around this is to separate the files into two separate destinations by using the same file filter, but adding a Conditional Split.
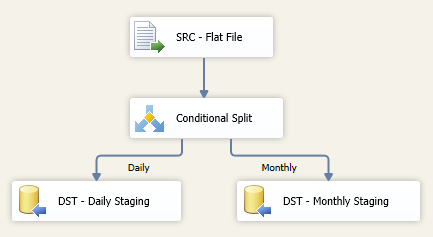
For the sake of simplicity, use the length of the ‘User::SourceFileName’ variable. Assume the company code length is static. The daily file name may be ‘Z:/Files/20151007AUTH9339.csv’, which has a length of 29, while the monthly file name may be ‘Z:/Files/201510AUTH9339.csv’ which has a length of 27, so we split them accordingly.

Now when we run the package, each file will end up in its respective destination as expected.
This is all fine and dandy for the simplest of situations, but there were obviously some package modifications made to accommodate such a simple change. We have also made several assumptions about file name variance. We assumed the company code would not change, when it most likely would.
Worst of all, the collection of files may expand to include quarterly or annual files. The impact of any of these assumptions changing, results in a more complicated and extensive solution. This solution needs more flexibility.
These groups of files are also interdependent and linear rather than parallel. Each file is looped over and processed one at a time. The optimal solution would be to process multiple groups of files at the same time. These groups are NOT dependent, so we should process them in PARALLEL. The technical requirement should be to process all monthly files in parallel with all daily files. This reduces our load time by using multiple threads and additional parallelism. This solution needs the capability of easily running multiple groups in parallel.
The solution is using a regular expression file filter and having multiple data flows.
The latter part of the solution is simple. Multiple data flows is easy, but how do we go about using a regular expression in a file filter? There is some flexibility with the FileSpec attribute, which allows expressions to be entered.

However, this is still not adequate. This does not allow for enough flexibility for unlimited file types, formats, naming conventions, etc.
The best way to achieve this is using a script task with C# or Visual Basic, leveraging their innate regular expression functionality. Either is acceptable, but I prefer the more commonly used C# standard.
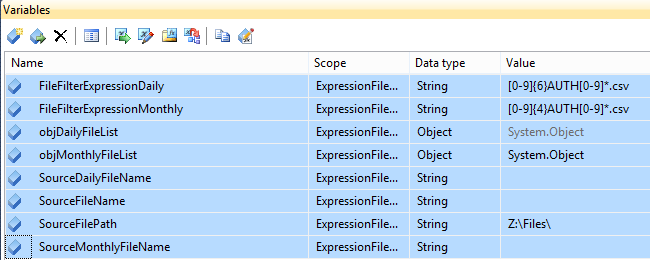
Create a file filter regular expression variable as a string, create another variable containing the file path for the source files, and finally, create an object variable that will contain all of the relevant file names.

Next, edit the script and replace the Main() function with the following:
public void Main()
{
string dirPath = (string)Dts.Variables["User::SourceFilePath"].Value;
string[] aryFiles = Directory.GetFiles(dirPath);
List<string> lstFiles = new List<string>();
string fileFilterExpression = (string)Dts.Variables["User::FileFilterExpression"].Value;
Regex filenameRegEx = new Regex(fileFilterExpression);
foreach (string fileName in aryFiles)
{
Match match = filenameRegEx.Match(fileName);
if (match.Success) lstFiles.Add(fileName);
}
Dts.Variables["User::objFileList"].Value = lstFiles.ToArray();
Dts.TaskResult = (int)ScriptResults.Success;
}
Connect the script task to the loop container as a predecessor and alter the loop container to use a different type of iteration. Rather than using the ‘Foreach From File Enumerator’, use the ‘Foreach From Variable Enumerator’. Set the Variable as ‘User::objFileList’. The Variable Mappings section will remain the same with the ‘User::SourceFileName’ Variable and the ‘0’ Index.
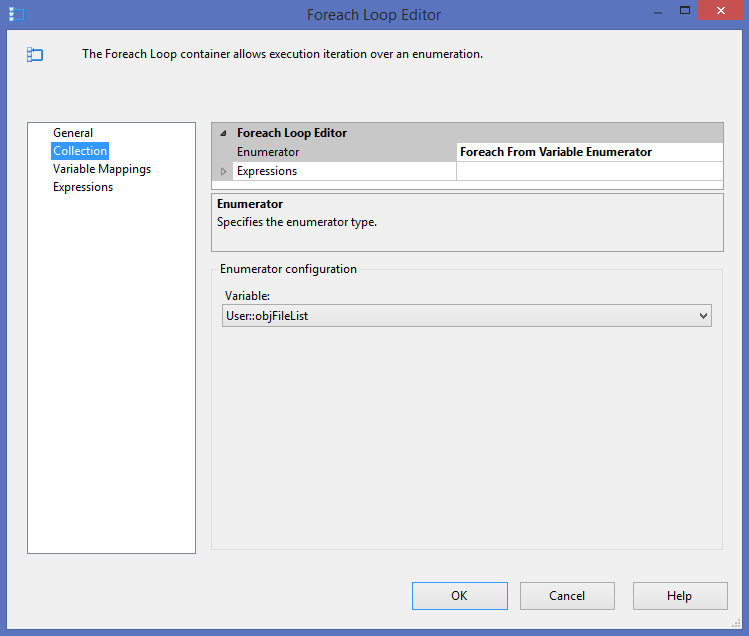
This is all that needs completed for one regular expression file filter. To run another group in parallel, start by duplicating the variables and alias them a bit more appropriately as follows:
Then copy and paste the script and data flow tasks, ensuring the object names are changed, the correct variables are used for each script component, and the data flow destinations are changed.

After completion, this should be a fully functional package that processes both daily and monthly files in parallel. There are no limitations to the file filtering, provided you know the regular expression syntax. I tend to use this Cheat Sheet reference, and sometimes a more advanced reference here.
